









AI 写的代码,单元测试到底该怎么写?

聊个最近让我挺纠结的事。
自从 Copilot、Cursor 这些东西铺开之后,我身边写代码的朋友明显分成了两派。一派是"AI 写完我就提 PR",另一派是"AI 写完我还得自己过一遍才敢合"。而让我纠结的,是夹在中间的那件事——AI 写的代码,单元测试该怎么写?
你可能觉得这是个伪命题:让 AI 自己写测试不就完了?我一开始也是这么想的。后来踩了几个坑之后,才意识到这事没那么简单。
"AI 给你写的测试,你敢直接跑吗"
说一个真实场景。
上个月我在做一个用户权限校验的模块,大概是个鉴权中间件。我让 AI 帮我写了一版,它确实写得不错——逻辑清晰,边界处理也到位。然后我顺嘴说了句"帮我写单元测试"。
出来的测试用例写得挺像那么回事:正常通过的、token 过期的、权限不足的,三类场景全覆盖。跑了一下,全绿。
但问题在哪?
问题在于它的测试用例和它的实现代码是"同源"的。AI 写了实现,又基于同一个实现写了测试,本质上就是在验证"这段代码确实在执行这段代码"。它测的是"代码有没有运行",而不是"逻辑对不对"。
我举个具体例子。AI 写的鉴权逻辑里,有个判断是 if (token && token.exp > Date.now())。它对应的测试用例构造了一个 exp 在过去的 token,断言返回 401。逻辑上没毛病。但如果我手写的时候不小心写成了 token.exp > Date.now() / 1000(毫秒和秒的混淆),AI 基于它自己写的代码生成的测试,是永远抓不到这个 bug 的。
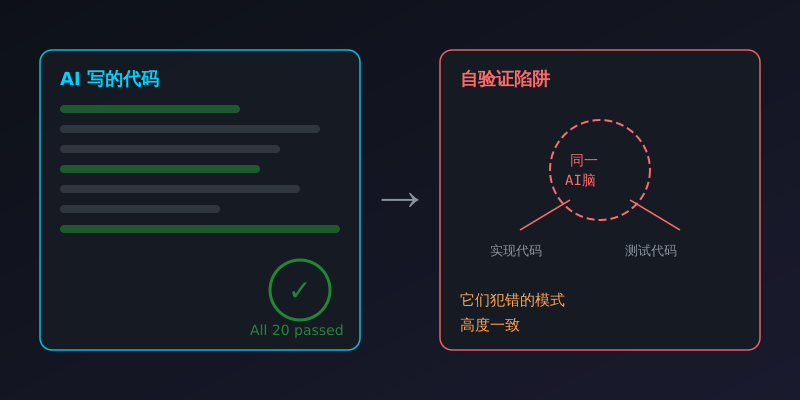 这就是"自验证陷阱"。测试代码和业务代码来自同一个 AI 脑子,它们犯错的模式高度一致。
这就是"自验证陷阱"。测试代码和业务代码来自同一个 AI 脑子,它们犯错的模式高度一致。
所以我的第一个结论是:AI 生成的测试,可以作为起点,但不能作为终点。你至少得人工审查一轮测试用例的"意图覆盖",而不仅仅是"行覆盖"。
"让 AI 写测试,本质上是在练你的提问能力"
既然让 AI 直接写测试有坑,那怎么做才能让它真正有用?
我的经验是,关键不在 AI,在你给它的上下文。说白了就是——你会不会"提问"。
先说反面案例。很多人让 AI 写测试就是一句话:
"帮我写这个函数的单元测试。"
然后 AI 就根据函数签名和实现,生成一堆看起来合理但本质上是在"复述逻辑"的测试。
再看正面案例。我现在让 AI 写测试,基本会提供这些东西:
第一,给它接口契约,而不是实现细节。 告诉它"这个函数的输入是什么、输出是什么、抛什么异常",但不要把实现代码一股脑丢给它。让它从接口层面去想"什么情况下会出问题"。
比如我会这样写 prompt:
以下是一个鉴权中间件的接口定义(TypeScript):
function authMiddleware(req: Request): AuthResult // 返回 { valid: boolean, userId?: string, error?: string } // 规则:Authorization header 中的 Bearer token // - 为空 → { valid: false, error: 'missing_token' } // - 过期 → { valid: false, error: 'token_expired' } // - 有效 → { valid: true, userId: 'xxx' } // - 格式错误 → { valid: false, error: 'invalid_format' }请为这个接口编写单元测试。重点关注边界条件和异常路径,不需要测实现细节。
你看,我给了它契约,但没给它实现。这样 AI 生成的测试就是从"需求"出发的,而不是从"代码"出发的。生成的用例会更接近真实用户的行为模式。
第二,给它明确的"不要测什么"。 AI 特别喜欢把所有东西都测一遍,包括那些 trivial 的赋值操作、getter/setter。如果你不告诉它边界,它会给你 20 个测试用例,其中 15 个在测没有意义的事情。
我通常会加一句:
不需要测简单的数据映射和纯赋值操作,专注于有分支逻辑和可能出错的地方。
第三,要求它列出"为什么测这个"。 这是我觉得最有效的一步。让 AI 在每个测试用例前面写注释,解释这个用例是为了覆盖什么风险。这样你审查的时候,不是在看代码,而是在看"思考过程"。
每个测试用例前请加注释,说明:这个用例在测什么场景,为什么这个场景有风险。

这三个步骤下来,AI 生成的测试质量会有质的提升。不是因为它变聪明了,而是因为你的 prompt 把它的搜索空间限制到了正确的地方。
"三类代码,三种测法"
不是所有 AI 生成的代码都用同一种策略来写测试。我的习惯是把 AI 写的代码分成三类,每类用不同的测试思路。
第一类:纯函数/工具函数。 这类最好测。数学计算、日期格式化、字符串处理之类的东西,输入输出完全确定。
这类直接让 AI 生成就行,几乎不用改。但有个细节——要让它覆盖"愚蠢输入"。比如日期格式化函数,让它测一下传入 null、空字符串、负数、超大数字会怎样。AI 默认不太会想到这些,因为它倾向于假设调用者是"正确"的。
第二类:有外部依赖的业务逻辑。 比如调数据库、调 API、读文件。这类是 AI 生成测试的重灾区。
AI 特别喜欢生成"mock 一切"的测试——mock 掉数据库、mock 掉 HTTP 请求、mock 掉文件系统,然后测一堆断言。问题是,这种测试经常变成"验证 mock 的行为符合预期",而不是验证业务逻辑。
我对这类代码的策略是:让 AI 写集成测试,而不是单元测试。 告诉它用真实的(或轻量级的)测试数据库、测试 API,测真实的调用链。牺牲一点速度,换真正的信心。
prompt 长这样:
这段代码会调用外部 API。请不要 mock HTTP 请求,而是使用 [msw / nock / 测试替身工具名] 拦截真实的请求,验证请求参数和响应处理逻辑。
第三类:UI 组件/交互逻辑。 前端同学经常遇到的。AI 写的 React/Vue 组件,测试怎么写?
我的建议是:只测用户行为,不测实现细节。 不要测组件内部的 state 变化,不要测某个 class name 有没有加上去。测的是:用户点了这个按钮,页面上出现了什么变化。
给 AI 的 prompt:
请使用 Testing Library 的理念编写测试:只查询和断言用户可见的文本、角色、可访问性标签,不查询 class name、不查询组件内部状态。

这三类分清楚之后,你会发现 AI 写测试的效率会高很多,因为你给它的指令是精准的,而不是一句"帮我写测试"然后在产出里挑毛病。
"那些踩过的坑"
最后聊几个我实际踩过的坑,给各位避避雷。
坑一:AI 生成的测试里混进了它自己的"合理推测"。 有一次我让 AI 给一个 API 接口写测试,它自动给返回的错误信息断言了一个它自己编的 message。结果真正的实现返回的错误信息措辞不同,测试直接挂了。后来我学会了在 prompt 里强调:断言时只验证 error code 或 error type,不要验证具体的 error message 文本。
坑二:snapshot 测试泛滥。 AI 特别喜欢生成 snapshot 测试,因为它不需要想"这个组件应该长什么样",直接 toMatchSnapshot() 就完事了。但 snapshot 测试在 AI 时代是个陷阱——你每次让 AI 改代码,它会同时改掉 snapshot,等于什么都没测。我现在会明确告诉 AI:
不要使用 snapshot 测试。所有断言都应该是明确的、有语义的。
坑三:测试数据太"完美"。 AI 生成的测试数据往往太规范了——用户名叫 "testUser",邮箱是 "test@example.com",年龄是 25。这当然能跑过,但真实世界的脏数据是什么样的?用户名带 emoji、邮箱超长、年龄是负数。我会要求 AI 在测试里混入一些"脏数据"场景,模拟真实的用户输入。
坑四:测了实现而不是测了行为。 这个前面也提过,但值得再强调。AI 倾向于根据实现写测试,这意味着一旦重构实现,测试全废。好的测试应该是"重构实现之后测试依然通过"的。实现变了,行为没变,测试就不用变。
行了,收个尾
说到底,AI 生成测试这件事,核心矛盾是:AI 擅长生成"看起来正确"的东西,但"看起来正确"和"真正正确"之间,差着你对业务的理解。
AI 能帮你覆盖 80% 的体力活——生成骨架测试、填充数据、补全边界条件。但剩下 20%,那些"为什么这个场景重要"、"这个边界条件在业务上意味着什么"的判断,还是得靠你自己。
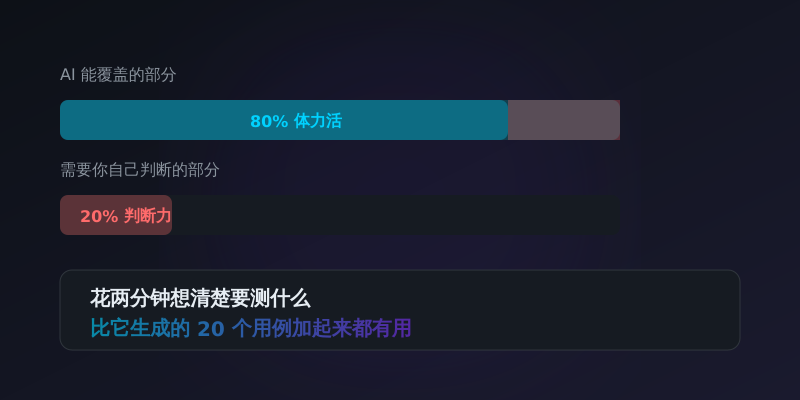
所以下次让 AI 写测试的时候,别只说"帮我写测试"。花两分钟想清楚你要它测什么、不要测什么、断言什么、忽略什么。这两分钟,比它生成的 20 个测试用例加起来都有用。
#AI编程 #单元测试 #Copilot #Cursor #代码质量 #测试驱动开发 #提示词工程 #软件工程 #程序员 #开发者 #AI提效 #测试策略 #技术写作 #工程实践 #代码审查
Q.E.D.

