









我们用 RAG 替掉了 Fine-tuning,效果反而更好了
不是所有问题都需要微调。这是一篇选型决策的真实复盘,聊聊我们团队踩过的坑和最后的结论。
先说结论
我们花了大概四周时间和四万块的 GPU 费用,证明了一件事:我们的场景不需要 Fine-tuning。
这听起来像一个很蠢的故事。但我觉得很多团队正在犯同样的错误,或者正在纠结要不要犯这个错误。所以写出来,帮你省点时间和钱。
我们的场景不复杂:一个企业内部的知识问答系统。员工问关于公司产品、流程、制度的问题,系统从内部文档里找答案。大概十万量级的文档,而且每个月都在更新。
一开始所有人都觉得,这不就是典型的 Fine-tuning 场景吗?把公司的知识"教"给模型,让它变成"公司专属 AI"。听起来逻辑通顺。
实际上坑很多。
Fine-tuning 的隐性成本,远比你想的高
显性成本大家都会算:标注几百条数据,租 GPU 跑几个小时,花个几千到几万块。这些确实不贵。
但隐性成本才是真正杀人诛心的。
数据标注。 你以为随便搞几百条 prompt-completion 对就行?不,你得保证数据质量。标注的人要懂业务,格式要统一,分布要合理。我们当时三个人标了两周,最后发现有一批数据标错了,又花了一周返工。
效果不可预期。 Fine-tuning 不是"喂数据→变聪明"这么简单。你加了 200 条数据,发现某些 case 变好了,另一些 case 反而变差了。为什么?不知道。调参就像玄学,学习率高了过拟合,低了没效果,数据量多了训练慢,少了效果不稳定。
最大的坑:数据更新。 我们公司的文档每个月都在变。产品在迭代,流程在调整,制度在更新。Fine-tuning 出来的模型是静态的——它学的是训练那一刻的数据快照。数据变了怎么办?重新标注、重新训练、重新部署。每次这个周期至少一周。而你的用户在这一周里拿到的是过期信息。
推理成本。 Fine-tuned 模型通常是独立部署的,你得自己管 GPU。十万个文档的场景,推理成本比调 OpenAI 的 API 贵了好几倍,而且还要操心显存、并发、扩容这些运维问题。

切到 RAG 之后发生了什么
我们在 Fine-tuning 的路上走了四周,最后决定停下来试试 RAG。
说实话,一开始团队里是有人反对的。觉得"我们都花了这么多功夫了,再坚持一下说不定效果就上来了"。这是典型的沉没成本谬误,我知道,但当时确实很难说服所有人。
最后是怎么说服的呢?很简单:我们拿同样的测试用例,跑了一遍 RAG 的 baseline,发现准确率已经到了 85%,而 Fine-tuning 搞了四周也才 88%。差距 3 个百分点,但 RAG 只用了三天就搭完了。
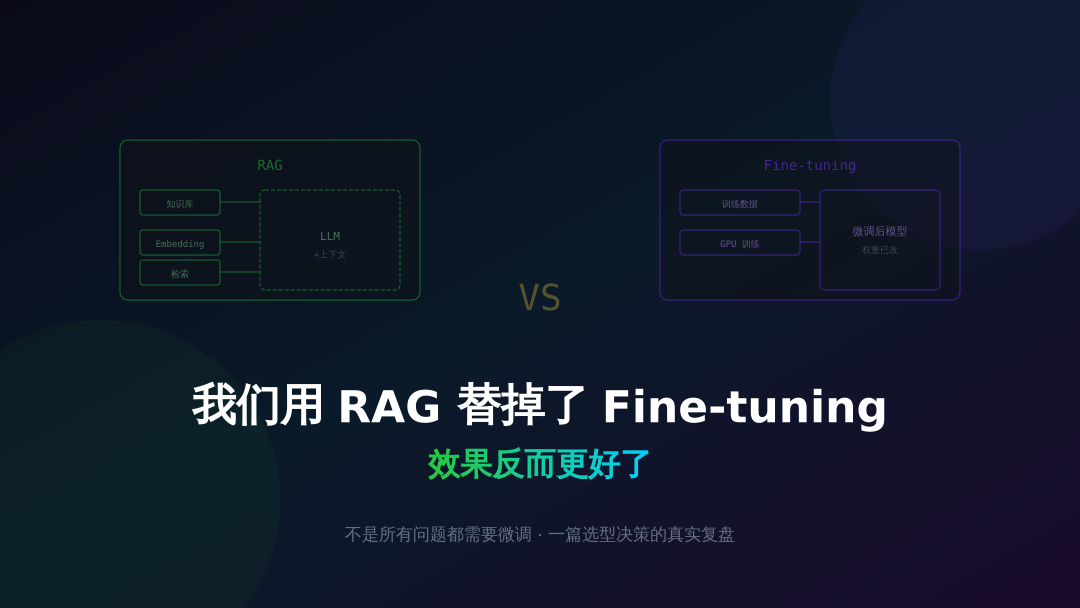
RAG 的逻辑其实很简单:不改模型本身,而是在每次提问的时候,从知识库里检索出相关文档片段,塞进 prompt 里当上下文。模型不"记住"你的知识,而是"看到"你的知识。
这个区别很关键:
- 知识更新是秒级的。 文档改了?重新向量化入库就行,不用重训模型。
- 推理成本可控。 用的是通用模型的 API,不用自己部署。
- 可解释性好。 用户问了一个问题,你能追溯到是哪几篇文档影响了回答,出了问题能定位。
- 数据标注需求极低。 你不需要 prompt-completion 对,你只需要一堆文档。
当然 RAG 也有它的问题。检索质量决定了回答质量,chunking 策略、embedding 模型、检索算法都需要调优。但这些调优是"确定性"的——你改了 chunk size,效果变好还是变差,你能感知到,也能理解为什么。不像 Fine-tuning,改了学习率你都不知道它为啥好了或者差了。

什么场景确实该用 Fine-tuning
说了这么多 RAG 的好话,我也得公平一点。Fine-tuning 不是没用,只是大部分团队用错了场景。
需要改变模型输出风格或格式的时候。 比如你需要模型严格按照某种 JSON schema 输出,或者你需要模型用特定的行业术语说话,或者你需要模型的回答风格统一(比如都用极简风格)。这些靠 prompt engineering 能做到 80 分,Fine-tuning 能做到 95 分。
任务本身就很简单,而且数据很稳定的时候。 比如情感分类、实体识别、文本摘要这类经典 NLP 任务。数据量大、标注质量高、任务定义清晰、数据很少变动——这四个条件都满足的时候,Fine-tuning 的性价比确实高。
延迟要求极高的场景。 RAG 多了一步检索,延迟会比纯模型调用高几十到几百毫秒。如果你的场景是实时对话,这个延迟可能是问题。不过说实话,大部分业务场景对这个延迟是无感的。
私有化部署、数据不能出域的场景。 如果你的数据敏感到不能走 API,需要本地部署,那 Fine-tuning 一个开源模型可能是唯一的选择。但这种情况,你其实也可以考虑本地部署 + RAG 的组合。
我们最后的结论是:先上 RAG,实在不够再考虑 Fine-tuning,而且大概率你会发现 RAG 够用了。
一个粗暴的判断方法
如果你还在纠结,试试这个方法:
问自己一个问题——你需要模型"记住"知识,还是"看到"知识?
如果是"记住"(比如模型要学会某种语言风格、输出格式),Fine-tuning 更合适。
如果是"看到"(比如模型要回答基于特定文档的问题),RAG 更合适。
90% 的企业场景,都是后者。
还有一条:如果你的数据每个月都在更新,Fine-tuning 基本可以排除了。除非你有钱有闲到每个版本都重新训一遍。
如果你也在做类似的选型,希望这篇能帮你少走弯路。有什么坑想聊的,评论区见。
#RAG #Fine-tuning #LLM #AI架构 #向量数据库 #Embedding #AI应用 #技术选型 #大模型 #知识库 #开发者 #工程实践 #Prompt #微调 #AI落地
Q.E.D.

