









你真的需要本地跑大模型吗?

不卖课、不贩卖焦虑、不搞成功学。Ollama 火了之后,好像每个开发者都在本地跑模型。但说实话,大部分人的使用场景根本不需要本地部署。这篇聊聊什么时候本地有意义,什么时候纯属浪费时间。
跟风的代价

我身边至少有五六个朋友,装了 Ollama,下了好几个模型,跑了一下"你好,介绍一下你自己",然后就再也没打开过。
这不是个别现象。你去 Reddit、V2EX、GitHub Issues 上看看,大量"我装了 Ollama 然后呢"的帖子。大家跟风装了本地模型,但不知道拿它干什么。显卡在烧,电费在涨,但实际使用价值约等于零。
为什么会这样?因为大部分人高估了"本地运行"的价值,低估了"能用"和"好用"之间的差距。
本地跑的模型,通常是开源模型的量化版本——Llama、Qwen、Mistral、DeepSeek 这些。7B、13B、70B 参数量的模型,效果差距巨大。7B 的模型在简单对话上还行,但你一旦要求它写代码、做推理、处理复杂指令,它的能力就跟云端的大模型差了好几个档次。
你本地跑一个 7B 的模型,得到的体验大概是 GPT-3.5 的水平。不是说不能用,但你已经有免费的 GPT-3.5 级别的 API 可以调了,何必自己烧显卡?
我有个同事买了张 4090,专门用来跑本地模型。结果他用了一个月,发现大部分时候还不如直接调 Claude API。4090 跑 70B 的模型推理速度还行,但显存只够跑 4-bit 量化的版本,效果打了不少折扣。后来他索性把 4090 留着打游戏了,AI 相关的工作全部走 API。
还有一个朋友更有意思。他在公司内网部署了一套 Ollama,跑了一个 13B 的模型,给团队用。初衷是好的——保护公司代码不外泄。但用了两周发现,13B 的模型写出来的代码 bug 率太高,团队花在 debug 上的时间反而比之前调 API 还多。最后换成了公司云上的私有化 API 方案,效果好了很多,成本也没贵多少。
真正需要本地的场景
说了这么多"不需要",也说说什么时候"需要"。

数据安全要求高的场景。 这是本地部署最硬的理由。如果你处理的是医疗数据、金融数据、法律文书,或者是公司的核心代码和商业机密,你确实不能把这些数据发到外部 API。这种情况下,本地部署不是可选项,是必选项。
但请注意:本地部署只是解决方案之一。很多云厂商现在提供了私有化部署的 API 服务——数据不出他们的云环境,但你也不需要自己运维模型。如果你的场景是"数据不能出公司"而不是"数据不能出我这台电脑",私有化 API 可能是更省事的选择。
离线环境。 如果你的工作环境没有稳定的网络连接——比如在飞机上、在偏远地区的项目现场、在网络受限的内网环境——本地模型是唯一的选择。但说实话,这种场景对大部分开发者来说不太常见。
超低延迟需求。 云端 API 的延迟通常在 200ms 到 2s 之间,取决于模型和网络状况。如果你的应用对延迟极其敏感(比如实时语音交互、游戏内 AI 对话),本地推理确实能提供更低的延迟。但前提是你有足够强的硬件——用 CPU 跑模型的延迟可能比调 API 还慢。
学习和研究。 如果你想深入了解模型推理的原理、量化技术的效果、不同模型的性能对比——本地部署是一个很好的学习途径。但这是"学习价值",不是"使用价值"。别把两者混为一谈。
定制和微调。 如果你需要基于开源模型做微调——用自己的数据训练一个专门领域的模型——那你确实需要本地环境。但微调和推理是两回事,需要的硬件配置也不一样。微调通常需要更强的 GPU,推理则相对轻松。
本地部署的隐性成本
很多人在做"本地 vs 云端"的对比时,只算了显卡和电费。其实隐性成本比你想的高。
维护成本。 模型更新了你要不要跟?CUDA 版本升级了兼容性有没有问题?显存不够了怎么优化?这些运维问题在云端都不用你操心,但在本地全都得自己搞定。如果你把花在折腾环境上的时间算进去,本地部署的"免费"就不再免费了。
模型质量。 量化是有损的。4-bit 量化的模型和全精度的模型,效果差距在某些场景下是很明显的。尤其是需要精确推理的任务——数学计算、代码生成、逻辑推理——量化模型更容易出错。你省了显存,但牺牲了质量。
上下文长度。 本地模型的可用上下文长度通常比云端短。8K、16K 是常见的上限,而云端 API 可以提供 32K、64K 甚至更长。如果你的工作流需要处理长文档、长代码库,本地模型的上下文限制是个实实在在的瓶颈。
功能缺失。 云端 API 通常附带一些实用功能——function calling、JSON mode、vision、多模态输入。开源模型对这些功能的支持参差不齐。你可能本地跑了一个文本模型,但发现它不支持 function calling,然后你的整个工具调用链都废了。
一个更实际的方案
如果你看到了这里,可能在想"那我到底该怎么办"。我的建议是这样的:
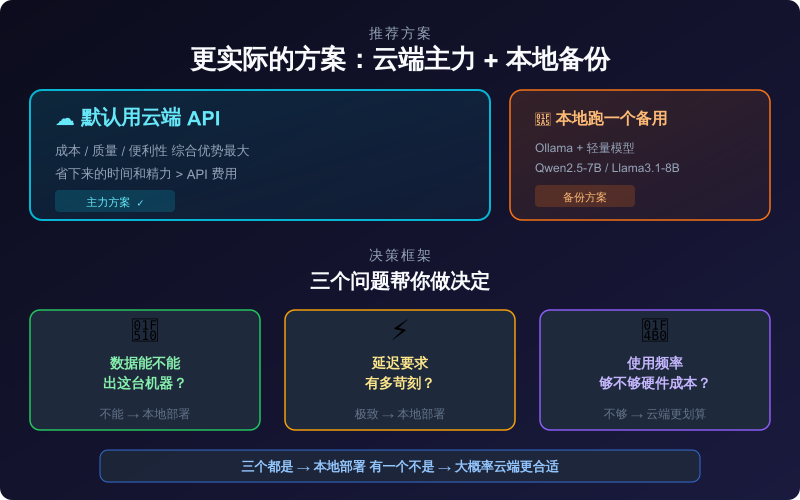
默认用云端 API。 除非你有前面说的那些特殊需求,否则云端 API 在成本、质量、便利性上的综合优势是本地部署比不了的。你省下来的时间和精力,比那点 API 费用值钱多了。
本地跑一个备用模型。 在你的机器上装一个 Ollama,下一个轻量级的模型(比如 Qwen3.5-7B 或 Llama3.1-8B),但只在特殊场景下用——网络断了、API 挂了、需要处理敏感数据。把它当备份方案,不是主力。
用 Ollama 做一些有趣的事。 如果你就是想玩玩本地模型,那就找一些云端 API 做不到或不方便做的事。比如:集成到你的终端里做一个本地化的 AI 助手、跑一个本地的代码补全服务、给你的 Home Assistant 加一个本地 AI 引擎。这些场景下本地模型的价值是真实的,不只是"跟风"。
算一笔真实的账。 如果你花 5000 块买了一张显卡来跑模型,先算算:这 5000 块够你调多少次 API?如果你一年调 API 的费用不到 500 块,那这张显卡要十年才能回本。当然,如果你本来就有一张游戏显卡,闲置的时候跑跑模型,那额外成本接近零,这种情况下本地部署确实没什么坏处。
说一个我自己的配置:我平时主力用 Claude API,一个月花费大概 200 块。本机用 Ollama 跑了一个 Qwen2.5-7B 做备用——在飞机上、网络差、或者需要处理一些不太方便发到外部的个人数据时用。这个组合用了半年,感觉很合理。本地模型不是主力,但有它在确实更安心。
还有一个很多人忽略的点:本地模型的学习价值。自己跑一个模型,你能直观感受到"模型大小和效果的关系"、"量化到底损失了什么"、"为什么有些任务怎么调 prompt 都不行"。这些体感比任何文章都有用。就算你最终决定不把本地模型当主力,这个学习过程本身就是收获。
我建议每个开发者至少花一个下午试试 Ollama。不用买显卡,就用你现有的电脑,下一个 7B 的模型跑一跑。体验一下本地推理的速度、感受一下量化后的效果损失、试试不同模型在同一任务上的表现差异。这个体验会让你对"本地 vs 云端"的判断更有依据,而不是跟着别人的帖子人云亦云。
行了,关于本地跑模型就聊这些。核心观点就一句话:本地部署是一个工具,不是信仰。它在特定场景下有价值,但不是所有人的刚需。别因为别人都在跑就跟风,先想清楚自己的需求再决定。
如果你确实需要本地部署,Ollama 是目前最省心的选择。装上就能用,支持的模型也多。但如果你只是想体验一下大模型的能力——开个 API 账户,花几毛钱调一次,体验大概率比你本地折腾半天要好。
最后说一个可能有用的思路:把"本地 vs 云端"的决策框架化。问自己三个问题:我的数据能不能出这台机器?我对延迟的要求是多少?我的使用频率够不够支撑硬件成本?如果三个问题的答案都是"需要本地",那你就本地部署。如果有一个答案是"不需要",大概率云端更合适。
说到底,工具选型跟技术选型一样——没有银弹,只有取舍。本地模型的取舍是"隐私和控制"换"便利和质量",大部分人在大部分场景下不需要做这个换。但如果你确实需要,现在工具已经够成熟了,放心上。
另外提一个趋势:端侧 AI 正在快速进步。手机上的大模型、笔记本上的 NPU、浏览器里的 WebGPU 推理——这些技术会让"本地跑模型"的门槛越来越低。可能再过一两年,你不需要专门买显卡、装 Ollama,手机上就能跑一个不错的模型。到那个时候,"本地 vs 云端"的讨论可能就不成立了——因为本地和云端的界限会变得模糊。
#本地大模型 #Ollama #开源模型 #LLM部署 #AI工具 #成本分析 #开发者 #GPU #模型推理 #量化 #API #DeepSeek #Llama #Qwen #技术选型
Q.E.D.

