










当你面对一个几GB大的日志文件,需要快速统计其中每个IP的访问次数时,你的第一反应是什么?打开PyCharm,import os,写一个循环,再维护一个巨大的字典?这套流程没问题,但如果我告诉你,在Linux命令行,一行命令就能搞定呢?今天,我们来重新认识一下那个你可能只用来 print $1 的“老朋友”——awk,揭开它作为“数据处理瑞士军刀”的真正面目。
破除偏见:awk 不仅仅是 print
在很多人的印象里,awk 的使命似乎就是打印某一列,比如:
ls -l | awk '{print $9}'
这无疑是大材小用了。awk 的名字来源于它的三位作者 Aho, Weinberger 和 Kernighan,它本质上是一种图灵完备的文本处理编程语言。它最强大的地方在于,它天生就是为了“逐行扫描、分析处理”这类任务而设计的。
awk 的核心思想可以用一个黄金公式来概括:
awk 'pattern { action }' filename
它会对 filename 中的每一行都执行一次这个逻辑:先判断该行是否匹配 pattern,如果匹配,就执行 action 中的代码。pattern 和 action 都是可选的,如果没有 pattern,则对每一行都执行 action。

awk 的魔法道具箱
要发挥 awk 的威力,你需要了解它的几个内置“魔法道具”:
- 字段变量:
$0: 代表整行内容。$1,$2, ...$n: 代表用分隔符切开后的第1、第2...第n个字段。NF(Number of Fields): 代表当前行有多少个字段,所以$NF就代表最后一个字段。
- 行号变量:
NR(Number of Records): 代表当前处理的是文件的第几行。
- 分隔符:
FS(Field Separator): 输入字段的分隔符,默认为空格或Tab。可以用-F参数在命令行指定,如awk -F':'。
- 特殊模式:
BEGIN: 在处理任何行之前执行的动作,常用于初始化变量。END: 在处理完所有行之后执行的动作,常用于计算和打印最终结果。
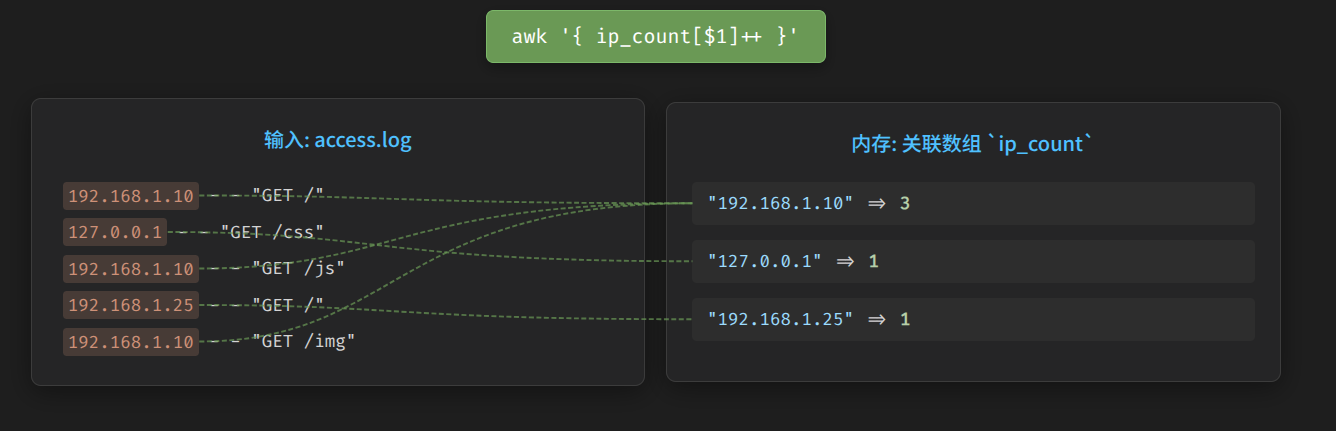
核心武器:无需声明的“关联数组”
如果说以上变量是 awk 的常规武器,那么“关联数组”(类似Python的字典或Java的HashMap)就是它的“核武器”,也是它能一行顶100行的底气所在。
在 awk 中,你不需要声明一个数组就可以直接使用它。
# 'ip_count' 就是一个关联数组,IP地址是key,出现次数是value
ip_count["192.168.1.1"]++
这个特性让 awk 在进行聚合统计时变得异常简单和强大。
实战场景:见证奇迹的时刻
光说不练假把式,我们来看三个经典场景,感受 awk 的威力。
场景一:网站日志分析 - 统计Top 10访问IP
需求:分析Nginx访问日志 access.log,找出访问次数最多的10个IP地址。
access.log 示例:
220.196.160.124 - - [02/Nov/2025:00:29:46 +0800] "GET / HTTP/1.1" 302 138 "-" "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36"
220.196.160.144 - - [02/Nov/2025:00:29:47 +0800] "GET / HTTP/1.1" 302 138 "-" "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36"
180.101.245.246 - - [02/Nov/2025:00:29:52 +0800] "GET / HTTP/1.1" 302 138 "-" "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36"
121.123.172.218 - - [02/Nov/2025:00:37:48 +0800] "GET /wp-login.php HTTP/1.1" 302 138 "" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:144.0) Gecko/20100101 Firefox/144.0"
217.156.65.242 - - [02/Nov/2025:00:46:20 +0800] "GET /.git/config HTTP/1.1" 302 138 "-" "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36"
219.144.89.44 - - [02/Nov/2025:01:02:18 +0800] "GET /c/strace.html HTTP/1.1" 302 138 "-" "Mozilla/5.0 (compatible; DotBot/1.2; +https://opensiteexplorer.org/dotbot; help@moz.com)"
113.219.202.173 - - [02/Nov/2025:01:03:20 +0800] "GET /c/nmcli.html HTTP/1.1" 302 138 "-" "Mozilla/5.0 (compatible; DotBot/1.2; +https://opensiteexplorer.org/dotbot; help@moz.com)"
113.219.202.44 - - [02/Nov/2025:01:03:24 +0800] "GET /c/semanage.html HTTP/1.1" 302 138 "-" "Mozilla/5.0 (compatible; DotBot/1.2; +https://opensiteexplorer.org/dotbot; help@moz.com)"
5.188.167.247 - - [02/Nov/2025:01:09:50 +0800] "GET /wp-content/plugins/WordPressCore/include.php HTTP/1.1" 302 138 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/133.0.0.0 Safari/537.36"
59.83.208.105 - - [02/Nov/2025:01:18:38 +0800] "GET /wp-content/plugins/WordPressCore/include.php HTTP/1.1" 302 138 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/133.0.0.0 Safari/537.36"
...
awk 一行搞定:
awk '{ip_count[$1]++} END {for (ip in ip_count) {print ip_count[ip], ip}}' access.log | sort -nr | head -n 10

命令分解:
awk '{ip_count[$1]++}':- 对每一行,
$1就是IP地址。 ip_count[$1]++这句代码就完成了统计:如果ip_count数组中没有这个IP,就创建它并设为1;如果已存在,就加1。
- 对每一行,
END {for...}:- 所有行处理完毕后,遍历
ip_count数组。 print ip_count[ip], ip打印出“次数 IP地址”的格式。
- 所有行处理完毕后,遍历
sort -nr: 将输出按第一列(次数)进行**数值(-n)降序(-r)**排序。head -n 10: 取排序后的前10行。
想象一下用Python实现这个功能,你需要读取文件、切分字符串、维护字典、排序字典...代码量远不止一行。
场景二:数据聚合 - 计算平均分
需求:有一个 scores.csv 文件,计算第二列(分数)的平均分。
scores.csv 示例:
Name,Score
Alice,88
Bob,92
Charlie,75
awk 一行搞定:
awk -F',' 'NR > 1 {sum+=$2; count++} END {if (count>0) print "Average:", sum/count}' scores.csv
命令分解:
awk -F',': 指定逗号为字段分隔符。NR > 1: 这是一个pattern,表示只处理行号大于1的行(跳过标题行)。{sum+=$2; count++}: 对每一行,将第二列的值累加到sum,同时计数器count加1。END {...}: 所有行处理完后,计算sum/count并打印结果。
场景三:文本转换 - 生成SQL语句
需求:将一个用户列表 users.txt 转换成可以直接执行的SQL INSERT 语句。
users.txt 示例:
101 Alice
102 Bob
awk 一行搞定:
awk '{printf("INSERT INTO users (id, name) VALUES (%s, \047%s\047);\n", $1, $2)}' users.txt
命令分解:
printf(...):awk内置了强大的printf函数,用于格式化输出。%s: 占位符,分别对应后面的$1和$2。\047: 这是单引号'的八进制转义,因为在awk的字符串中直接写单引号会引起冲突。
输出结果:
INSERT INTO users (id, name) VALUES (101, 'Alice');
INSERT INTO users (id, name) VALUES (102, 'Bob');
更进一步:成为 awk 高手
当然,awk 的能力远不止于此,它还支持自定义函数、循环、判断等复杂的编程逻辑。今天的文章只是为你打开了一扇门。
如果你渴望深入探索 awk 的所有高级特性,成为真正的命令行大师,推荐阅读这份非常全面的 awk 命令详解:https://linux.alianga.com/c/awk.html

何时选择 awk?
awk 并非要取代Python或Go,但在处理基于行的、有结构化规律的文本数据时,它几乎是无可匹敌的王者。
- 优点:无需编译、无需安装额外依赖(系统自带)、处理速度极快、与管道命令(
|)完美结合。 - 适用场景:日志分析、数据清洗、报表生成、文本格式转换。
当然,如果你的逻辑非常复杂,需要处理JSON/XML,或者要与API交互,那么功能更全面的Python等脚本语言无疑是更好的选择。
掌握 awk,就像给你的命令行配上了一把削铁如泥的瑞士军刀。下次再遇到文本处理任务时,不妨先停下打开IDE的手,试试这门古老而强大的“黑魔法”吧!
你还知道哪些 awk 的神奇用法?欢迎在评论区分享你的独门秘籍!
Q.E.D.

