










AI 写的测试,到底能不能信
不卖课、不贩卖焦虑、不搞成功学。单元测试是 AI 最擅长的场景之一,但"写得快"和"测得准"完全是两回事。这篇聊聊 AI 生成测试的常见坑,以及我的一些踩坑经验。
测试是 AI 的舒适区
如果你问一个开发者"AI 最擅长写什么",十有八九会提到测试。
这不奇怪。测试用例有明确的输入输出、标准的结构(setup-act-assert)、成熟的框架(Jest、PyTest、JUnit),而且大部分测试都是模式化的——给一个输入,断言一个输出,覆盖正常和异常情况。这些特点恰好是 AI 的强项。
我自己也是这么用的。写完一个函数,直接让 AI 生成测试用例。十次里有八次,生成的测试覆盖得比我手动写的还全面——因为我手动写测试经常偷懒,只写 happy path,AI 不会偷懒,它会把边界条件、空值、异常类型都给你写上。
所以 AI 写测试好用吗?好用。但能不能信?这就复杂了。
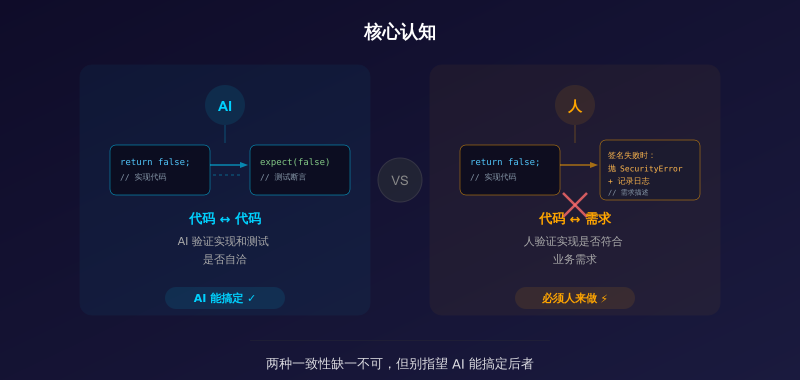
让我举个真实的例子。我之前写了一个处理支付回调的函数,逻辑不算复杂——验证签名、解析数据、更新订单状态、发送通知。让 AI 生成测试,它给我写了 15 个测试用例,覆盖了签名验证失败、数据格式错误、订单不存在、重复回调等场景。覆盖率 94%,看起来很完美。
然后我仔细看了断言内容,发现问题:AI 生成的测试里,"签名验证失败"的测试断言的是"函数返回了 false",但实际上正确的业务逻辑应该是"抛出 SecurityError 并记录日志"。AI 看到我的实现确实是返回了 false,所以忠实地区测了这个行为——但这个行为本身就是 bug。
这就是 AI 写测试最隐蔽的问题:它会帮你"验证"你的 bug。
三种常见的坑

用了大半年 AI 生成测试,我踩过的坑大致可以归为三类。
第一种:测试了错误的东西。 AI 生成的测试,经常出现"断言跟实现一致,但实现本身就是错的"这种情况。比如你的函数应该在输入为负数时抛出异常,但你的实现写成了返回零。AI 生成的测试会断言"输入负数时返回零"——测试通过了,但逻辑是错的。
为什么会这样?因为 AI 在生成测试的时候,很大程度上是在"复述"你的实现逻辑。如果你的实现有 bug,AI 的测试也会忠实地"测试"这个 bug,而不是发现它。换句话说,AI 写的测试能验证"代码跟代码自己一致",但不能验证"代码跟需求一致"。
第二种:过拟合实现细节。 AI 生成的测试经常耦合到实现细节上。你重构了一个函数的内部实现(功能没变),AI 之前的测试就挂了。因为它断言的是内部调用了什么方法、中间变量是什么值,而不是函数的外部行为。
好的测试应该验证"行为",而不是"实现"。但 AI 在生成测试的时候,它能看到你的实现代码,所以它天然倾向于测试实现细节。你需要手动把那些过度耦合的断言删掉或者改掉。
第三种:用 Mock 偷懒。 AI 特别喜欢用 Mock。一个函数调用了三个外部依赖,AI 会把三个全 Mock 掉,然后测试函数内部逻辑。这在某些场景下是对的——如果你真的只想测这个函数本身。但在另一些场景下,Mock 掉所有依赖意味着你没有测到真正的集成行为。
我见过一个 AI 生成的测试套件:十二个测试用例,Mock 了所有外部调用,全部通过。然后我跑了一下集成测试,三个 bug。因为那些 Mock 掉的依赖之间的交互才是问题所在,但单元测试完全没覆盖到。
怎么用 AI 写更好的测试
说了这么多坑,也说说怎么扬长避短。

让 AI 写测试,但自己写断言。 这是我目前最常用的方式。让 AI 生成测试的框架——setup、test case 结构、数据准备——这些样板工作它做得又快又好。但关键的断言部分,我自己写或者至少自己审。"这个函数的输出应该是什么"这种判断,目前还是人来做更靠谱。
给 AI 需求,而不是给 AI 实现。 如果你让 AI 根据你的实现代码生成测试,它会倾向于"复述实现"。但如果你给它的是需求描述——"这个函数接收一个用户 ID,返回用户信息,如果用户不存在应该抛出 NotFoundError"——它生成的测试会更接近真正的行为验证。
这个区别很关键。"基于实现生成测试"和"基于需求生成测试"是两种完全不同的方式。前者更快但更容易有盲区,后者更慢但更可靠。
别全信覆盖率报告。 AI 生成的测试通常能把覆盖率拉得很高——80%、90% 甚至 100%。但覆盖率高不等于质量高。AI 可以通过很 trivial 的方式覆盖每一行代码,但完全没有测试到关键的业务逻辑。看覆盖率报告的时候,关注的不只是数字,还要看那些测试到底在断言什么。
用 AI 生成"对手测试"。 与其让 AI 生成"验证正确性"的测试,不如让它生成"尝试破坏"的测试。"帮我写几个测试,试图找到这个函数的 bug"——这种对抗性的测试方式,AI 做起来意外地好。因为它没有"我的代码是对的"这个心理包袱,它会真的去想各种边界情况。
手动写集成测试。 单元测试可以大量依赖 AI 生成,但集成测试还是自己写比较靠谱。集成测试的核心价值在于验证"组件之间的交互",这需要对系统整体有理解。AI 目前对跨模块的上下文理解不够,生成的集成测试经常是"把几个单元测试拼在一起",没有真正测到集成逻辑。
一个更根本的问题
聊到这,我想说一个更根本的问题:我们为什么写测试?
大部分人会说"为了验证代码的正确性"。这个回答没错,但不完整。测试的另一个重要价值是"作为设计的约束"——当你知道代码需要被测试的时候,你会倾向于写出更容易测试的代码。接口更清晰、依赖更明确、副作用更少。
这个价值是 AI 给不了的。AI 可以帮你写测试,但它没法替你做"为了让代码可测试而调整设计"的决定。如果你在写代码的时候完全不考虑测试,让 AI 事后补测试——你得到的是覆盖率报告上的数字,不是真正的质量保证。
好的测试文化不是"写完代码让 AI 生成测试",而是"在写代码的时候就考虑怎么测"。AI 是这个过程中的工具,不是替代品。
我现在的习惯是这样:写代码之前先想清楚"这个函数的输入输出是什么、有哪些边界情况",然后把这个想法写成一段自然语言描述。这段描述既是给自己的设计文档,也是给 AI 生成测试的 context。AI 基于这段描述生成测试,我再手动检查断言是否覆盖了我的预期。
这个流程比"写完代码让 AI 生成测试"多了一个步骤,但效果好了很多。因为 AI 生成的测试是基于"我的设计意图"而不是"我的实现细节",所以测试更健壮、重构之后不容易挂。
还有一个经验:对于核心业务逻辑的测试,我会让 AI 生成两套——一套正常流程的测试,一套对抗性的测试。对抗性测试就是"试图找到这段代码的 bug"。有时候对抗性测试能找到一些正常流程测不到的边界情况。AI 在这个场景下特别有用,因为它没有"我知道这段代码是对的"这个心理包袱。
最后说一个让人不太舒服的事实:如果你完全依赖 AI 写测试,你的测试能力会退化。就像你长期用计算器,心算能力会下降一样。偶尔自己手写几个测试,保持对测试思维的感觉,还是有必要的。不是说每次都要手写,但别让自己变成"离开 AI 就不会写测试"的状态。
行了,关于 AI 写测试就聊这么多。
总结一句话:AI 写的测试,能用,但要挑着用。框架让它搭,断言自己把关。覆盖让它跑,关键逻辑自己审。别被高覆盖率骗了——测试的意义在于它断言了什么,而不在于它覆盖了多少行。
如果只能记住一个原则,那就是:AI 生成的测试验证的是"代码跟自己的一致性",只有你手动写的断言才能验证"代码跟需求的一致性"。这两种一致性缺一不可,但别指望 AI 能替你搞定后者。
还有一个实际操作上的建议:给你的项目建一个测试规范文档,列出哪些场景必须手写测试、哪些可以用 AI 生成、断言的标准是什么。这个文档同时给团队成员和 AI 看——团队成员知道标准,AI 知道你的期望。有了这个文档之后,AI 生成的测试质量会稳定很多,因为它有了一个明确的"好的测试长什么样"的参考。
说到底,AI 写测试最大的价值不是"帮你省时间",而是"帮你覆盖你懒得覆盖的边界情况"。人类写测试的毛病是偷懒——只写 happy path,边界情况能跳就跳。AI 不会偷懒,它会老老实实地把所有边界都写上。你只需要把关断言是否正确就行。这个"AI 负责覆盖、人负责判断"的模式,我觉得是目前最合理的分工。
#AI测试 #单元测试 #代码质量 #测试覆盖 #Cursor #AI编程 #软件测试 #TDD #Jest #开发者效率 #Mock #集成测试 #测试驱动开发 #工程实践 #自动化测试
Q.E.D.

