









别再裸调 API 了:一个 AI 应用的工程化架构长什么样
写给正在把 AI 塞进项目的你。不讲模型原理,只聊工程实践——从 demo 到生产,中间到底差了什么。
你的 demo 跑通了,然后呢
我见过太多这样的场景了。
周末 hackathon,三个人憋了两天,拿 OpenAI 的 API 搭了个聊天机器人,前端还是用的 Streamlit,demo 的时候全场叫好。周一回去,leader 说"不错,下个季度上线"。
然后就没有然后了。
Demo 里的代码是什么样的?你我都写过。一个 Python 文件,三百行,硬编码的 API key,prompt 全是字符串拼接,错误处理?不存在的,大不了 try-catch 吞掉。输出质量全靠模型当天的运气,偶尔跑飞了就在群里说"这个 case 不太行"。
这套东西能跑 demo,能拿奖,能让你在面试的时候讲一个好故事。但你把它丢到生产环境里试试?API 限流了怎么办?模型升级了 prompt 效果变了怎么办?token 费用涨了十倍怎么办?用户投诉回答质量差你怎么排查?
Demo 和生产之间的距离,不是"再加几个 feature",而是整个架构层面的差距。

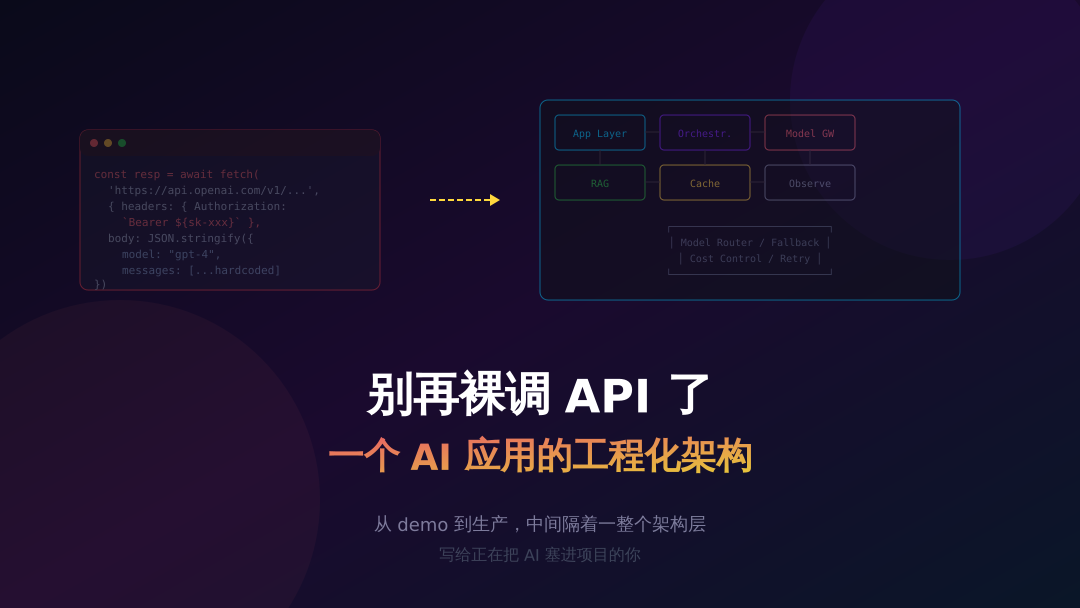
一个 AI 应用到底需要哪些层
说一个我觉得比较实用的分层方式。不是什么教科书上的标准答案,就是我自己踩坑之后总结出来的,能覆盖大部分场景。
最上面是应用层,就是你的用户直接交互的东西——Web 界面、API 接口、CLI 工具,或者嵌在现有产品里的某个功能模块。这层没什么好说的,该怎么做还怎么做。
往下是编排层。这层是很多人的盲区。你的应用不是只有一个 prompt 打到模型就完事了,对吧?可能需要先做意图识别,再根据意图路由到不同的 prompt 模板,有些场景要调用外部工具(查数据库、调搜索引擎),拿到结果再二次加工。这一整套流程的管理和调度,就是编排层在干的事。LangChain 算是这个领域最出名的框架了,但说实话,很多时候你不需要那么重的东西,自己写一个轻量的 pipeline 反而更好维护。
再往下是模型网关。这是我最想强调的一层。它的作用是把底层的模型调用统一抽象起来,让你的应用代码不直接依赖任何一家模型提供商。为什么要这样?因为你迟早会碰到这些事:OpenAI 那边挂了,你需要自动切到 Claude;某个任务用 GPT-4o 性价比更高,另一个任务需要 Claude 的长上下文能力;你想给不同用户设置不同的 token 额度;你想统计每个功能模块烧了多少钱。
如果你是裸调 API,每换一个模型就要改一坨代码。有了模型网关,这些都是配置层面的事情。
然后是上下文引擎和缓存层。上下文引擎说白了就是 RAG——用户问了一个问题,你得从知识库里捞出相关的片段塞进 prompt 里,不然模型就是在瞎编。缓存层更直接了,有些高频问题你根本不应该每次都调模型,语义相似的问题直接返回缓存结果,省钱又省延迟。
最底下那层是可观测性。日志、链路追踪、效果评估、成本看板。很多团队一开始觉得这东西不重要,等出了问题才发现自己是瞎的——不知道哪个用户的哪个请求跑了飞了,不知道为什么这周的 token 用量突然翻倍,不知道 prompt 改了之后效果是变好还是变差了。

几个我个人觉得最值钱的实践
架构图谁都能画,真正值钱的是你踩过坑之后才知道的那些细节。
模型网关要做成薄的。 我见过有团队把模型网关做成了一个巨无霸,里面塞了 prompt 管理、上下文组装、甚至业务逻辑。别这样。网关就干三件事:路由、限流、计费。其他的都往上层推。网关越薄,换模型的成本越低。你自己封装一个统一的 call 接口,底层支持 OpenAI、Anthropic、本地模型的适配器,切换的时候改一个配置字段就行。
Prompt 一定要版本管理。 我之前吃过这个亏。一个 prompt 跑了两周效果不错,某天心血来潮改了几个词,效果突然变差了,但我不确定是改坏了还是模型那天抽风。后来我才反应过来——我连改之前的版本都没留。从那以后我把 prompt 当代码管,每次改动都走 git,改完跑一轮评估用例才上线。说起来像废话,但真的很多团队没做。
缓存别只做精确匹配。 "今天天气怎么样"和"今天天气如何"意思一样,精确匹配的缓存命中不了。语义缓存是值得投入的,用向量相似度做匹配,命中率能提升不少。当然你也不用一步到位,先加一个 embedding 层做近似匹配,效果就比没有强很多。
评估要自动化,不能只靠人肉测试。 你改了 prompt、换了模型、调了参数,怎么知道效果变好还是变差?靠人肉点几个 case 看看?效率太低了,而且会不自觉地只看表现好的 case。搞一个 eval pipeline,攒一批有标注的测试用例,每次改动自动跑,出一个分数和 diff 报告。不用很复杂,哪怕就是一个 JSON 文件存着 input/expected_output,CI 里跑一遍比对就行。
一定要做 fallback,而且要优雅降级。 OpenAI 挂了不是小概率事件,你不能让用户看到一个 500 错误就完事了。至少做到:主模型超时 → 自动切到备选模型 → 备选模型也不行 → 返回一个兜底的静态结果或者"系统繁忙"提示,同时把错误信息记下来,你事后能排查。三级 fallback 不算多。

要不要用框架
这是个被问了无数遍的问题。
我的看法是:看阶段。
原型阶段,LangChain、LlamaIndex 这些框架确实能帮你快速搭起来。它们帮你封装了很多底层细节,让你专注于业务逻辑。
但当你进入生产阶段,你可能会发现框架帮你做了一百件事,但其中八十件你不需要,剩下二十件你需要自定义但框架的抽象层让你改起来很痛苦。这时候你可能得把框架拆掉,自己重写。
所以我的建议是:用框架学思路,不要用框架当依赖。理解它为什么这么设计,然后自己实现一个精简版的。你的场景远没有框架考虑的那么复杂,一个几百行的轻量编排层就够了。
另外一个选择是看看更新的工具。LiteLLM 做模型网关很轻量,Semantic Kernel 的编排设计比较克制,DSPy 用编程的方式管理 prompt 听起来反直觉但确实解决了版本化的问题。不一定非要追 LangChain 那条路。
最后
写这篇文章不是为了给你画一个大饼然后说"你必须做到以上所有"。
不是的。你的团队可能就三五个人,你可能只有一个 AI 功能模块嵌在现有产品里,你可能连专职的 MLOps 都没有。
但哪怕只是做到:把 API key 从代码里抽出来放到环境变量里,给 prompt 加上版本管理,做一层简单的模型调用封装——你就已经比大部分团队走得远了。
架构不是为了在技术分享会上吹牛用的,是为了让你半夜被告警叫醒的时候,能快速定位问题,然后接着睡。
先做到能睡安稳觉,再谈其他的。
觉得有用的话转发给你的队友。架构这事儿,一个人想清楚不如一群人聊清楚。
#AI应用 #工程化 #LLM #架构设计 #RAG #LangChain #API #模型网关 #Prompt #可观测性 #MLOps #开发者 #技术架构 #AI工程 #生产环境
Q.E.D.

